Aprovado na PGE-CE: Ayrton Mesquita
Aprovado na PGE-CE: Ayrton Mesquita
Julgue os próximos itens, a respeito de computação na nuvem, sistemas de informações e teoria da informação.
39 A informação se caracteriza pela compreensão e internalização do conteúdo recebido, por meio do seu uso em nossas ações; o dado, por sua vez, é um elemento bruto dotado apenas de significado e relevância que visem fornecer uma solução para determinada situação de decisão.
Comentário: Essa questão tem um erro na definição de dado. O dado não possui significado e relevância. Logo, temos uma alternativa incorreta.
Gabarito: 39. E.
Acerca de banco de dados, julgue os seguintes itens.
40 Situação hipotética: Ao analisar um computador, Marcos encontrou inúmeros e-mails, vídeos e textos advindos, em sua maioria, de comentários em redes sociais. Descobriu também que havia relação entre vários vídeos e textos encontrados em um diretório específico. Assertiva: Nessa situação, tendo como referência somente essas informações, Marcos poderá inferir que se trata de um grande banco de dados relacional, visto que um diretório é equivalente a uma tabela e cada arquivo de texto é equivalente a uma tupla; além disso, como cada arquivo possui um código único, poderá deduzir que esse código é a chave primária que identifica o arquivo de forma unívoca.
41 A mineração de dados se caracteriza especialmente pela busca de informações em grandes volumes de dados, tanto estruturados quanto não estruturados, alicerçados no conceito dos 4V’s: volume de mineração, variedade de algoritmos, velocidade de aprendizado e veracidade dos padrões.
42 Descobrir conexões escondidas e prever tendências futuras é um dos objetivos da mineração de dados, que utiliza a estatística, a inteligência artificial e os algoritmos de aprendizagem de máquina.
Comentário: Vamos comentar cada uma das afirmações acima.
Gabarito: 40. E. 41. E 42. C.
Com relação à programação Python e R, julgue os itens que se seguem.
43 Considere os comandos a seguir, na linguagem R, os quais serão executados no ambiente do R, e considere, ainda, que > seja um símbolo desse ambiente.
> helloStr <- “Hello world!”
> print(helloStr)
Nesse caso, após a execução dos comandos, será obtido o resultado a seguir.
[1] “Hello world!”
44 Considere os seguintes comandos na programação em Python.
a = ” Hello, World! ”
print(a.strip())
Esses comandos, quando executados, apresentarão o resultado a seguir.
a[0]=Hello,
a[1]=World!
Comentário: Vamos comentar cada uma das afirmações acima.
Gabarito: 43. C. 44. E.
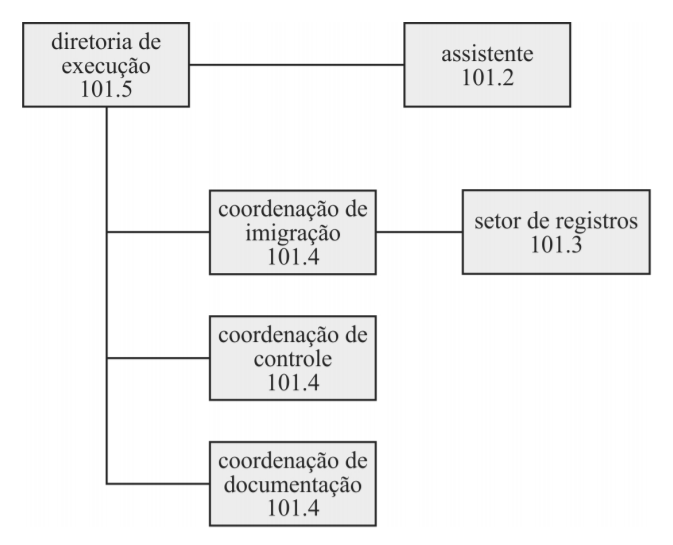
As informações de um departamento e de seus colaboradores devem ser organizadas e armazenadas conforme a estrutura mostrada no diagrama precedente. Para isso, serão utilizados os comandos DDL a seguir.
create table organograma (
id integer primary key,
descricao varchar(50),
cargo varchar(50),
pai integer,
constraint fk_organograma foreign key (pai) references organograma (id)*
);
create table colaborador (
cpf bigint primary key,
nome varchar(50),
data_nascimento date );
create table colaborador_organograma (
cpf bigint,
cargo integer,
data_nomeacao date,
data_exoneracao date,
constraint pk_colaborador_organograma primary key (cpf, cargo),
constraint fk_colaborador_organograma_cpf foreign key (cpf) references colaborador (cpf)*,
constraint fk_colaborador_organograma_cargo foreign key (cargo) references organograma (id)
);
* Comentário do professor: dependendo do SGBD é necessário colocar o nome do atributo que será referenciado na tabela.
Tendo como referência as informações apresentadas, julgue os próximos itens.
51 A tabela colaborador está na primeira forma normal.
52 A seguir, é apresentado o diagrama entidade-relacionamento correto para os comandos DDL em questão.

53 A seguir, são apresentadas as expressões SQL corretas para inserir na tabela organograma as informações constantes do diagrama apresentado.
insert into organograma (id, descricao, cargo, pai) values (1, ‘assistente’, ‘101.2’, 2);
insert into organograma (id, descricao, cargo, pai) values (2, ‘coordenação de imigração’, ‘101.4’, 1);
insert into organograma (id, descricao, cargo, pai) values (3, ‘coordenação de controle’, ‘101.4’, 1);
insert into organograma (id, descricao, cargo, pai) values (4, ‘coordenação de documentação’, ‘101.4’, 1);
insert into organograma (id, descricao, cargo, pai) values (5, ‘setor de registros’, ‘101.3’, 3);
insert into organograma (id, descricao, cargo) values (6, ‘diretor de execução’, ‘101.5’);
54 O comando SQL a seguir permite apagar o conteúdo da tabela colaborador_organograma.
delete from colaborador_organograma;
55 Depois de executados os comandos SQL a seguir, nenhum registro será inserido na tabela colaborador.
BEGIN TRANSACTION;
INSERT into colaborador values (‘11111111111’, ‘Clark Stark’, ’01-03-1963′);
INSERT into colaborador values (‘22222222222’, ‘Antonio Parker’, ’03-08-1962′);
ROLLBACK;
END TRANSACTION;
56 Em uma transação, durabilidade é a propriedade que garante que os dados envolvidos durem por tempo necessário e suficiente até que sejam excluídos.
Comentário: Vamos comentar as afirmações acima.
PS.: Tentei executar o SQL no site sqlfiddle.com. O código está abaixo se você quiser fazer alguns testes. Usei o MySQL.
create table organograma (
id integer primary key,
descricao varchar(50),
cargo varchar(50),
pai integer,
constraint fk_organograma foreign key (pai) references organograma (id) );
create table colaborador (
cpf bigint primary key,
nome varchar(50),
data_nascimento date );
create table colaborador_organograma (
cpf bigint,
cargo integer,
data_nomeacao date,
data_exoneracao date,
constraint pk_colaborador_organograma primary key (cpf, cargo),
constraint fk_colaborador_organograma_cpf foreign key (cpf) references colaborador (cpf),
constraint fk_colaborador_organograma_cargo foreign key (cargo) references organograma (id) );
insert into organograma (id, descricao, cargo, pai) values (1, ‘assistente’, ‘101.2’, null);
insert into organograma (id, descricao, cargo, pai) values (2, ‘coordenação de imigração’, ‘101.4’, 1);
insert into organograma (id, descricao, cargo, pai) values (3, ‘coordenação de controle’, ‘101.4’, 1);
insert into organograma (id, descricao, cargo, pai) values (4, ‘coordenação de documentação’, ‘101.4’, 1);
insert into organograma (id, descricao, cargo, pai) values (5, ‘setor de registros’, ‘101.3’, 3);
insert into organograma (id, descricao, cargo) values (6, ‘diretor de execução’, ‘101.5’);
insert into colaborador (cpf, nome, data_nascimento) values (1, ‘Thiago Cavalcanti’, ‘2018-09-17’);
insert into colaborador (cpf, nome, data_nascimento) values (2, ‘Flavia Cavalcanti’, ‘2018-09-17’);
insert into colaborador (cpf, nome, data_nascimento) values (3, ‘Vinicius Cavalcanti’, ‘2018-09-17’);
INSERT into colaborador values (‘11111111111’, ‘Clark Stark’, ‘1963-03-01’);
INSERT into colaborador values (‘22222222222’, ‘Antonio Parker’, ‘1962-08-03’);
Gabarito: 51. C. 52. E 53. E 54. C. 55. C 56. E
Acerca de banco de dados, julgue os itens seguintes.
57 Em um banco de dados relacional, os dados são armazenados em tabelas; e as tabelas, organizadas em colunas.
58 NoSQL são bancos de dados que não aceitam expressões SQL e devem ser armazenados na nuvem.
Comentário: Vamos comentar cada uma das alternativas acima.
Gabarito: 57. C 58. E
No que se refere aos conceitos de estratégias de distribuição de banco de dados, julgue os itens que se seguem.
59 Na replicação síncrona, recomenda-se que os bancos de dados fiquem armazenados em sítios geograficamente distantes entre si, pois a execução da replicação ocorrerá com um atraso, que varia de poucos minutos a horas.
60 Disponibilidade de um sistema de banco de dados distribuído é, por definição, a característica de o sistema estar sempre disponível para ser utilizado imediatamente
Comentário: Vamos comentar cada uma das alternativas acima.
Gabarito: 59. E 60. C
Qualquer dúvida estou às ordens,
Forte abraço e bons estudos,
Thiago Cavalcanti