Apresentamos abaixo as questões da prova do TRT-PA devidamente comentadas para o cargo de analista judiciário de TI.
CREATE TABLE predio
(
id numeric(7,0),
nome varchar(50),
local varchar(150),
mnemonico varchar(10),
CONSTRAINT pk_sede PRIMARY KEY (id),
CONSTRAINT uq_sede UNIQUE (mnemonico)
);
CREATE TABLE salas (
codigo numeric(7,0) NOT NULL,
local varchar(10),
descricao varchar(50),
area numeric(10,2),
CONSTRAINT pk_salas PRIMARY KEY (codigo),
CONSTRAINT fk_sede_sala FOREIGN KEY (local)
REFERENCES predio (mnemonico)
);
Considerando os algoritmos acima, em que são criadas as tabelas predio e salas, assinale a opção cuja expressão SQL apresenta informações do registro da maior sala existente.
A select c1.local, c1.nome, c2.descricao, c2.area
from predio as c1, salas as c2
where c2.local=c1.mnemonico
having max(c2.area)
B select c1.local, c1.nome, c2.descricao, max(c2.area)
from predio as c1, salas as c2
where c2.local=c1.id
group by c1.local, c1.nome, c2.descricao
C select c1.local, c1.nome, c2.descricao
from predio as c1, (
select local, descricao, area from salas as c1
where area = (select max(area) from salas as
c2 where area>0)
) as c2 where c2.local=c1.mnemonico;
D select c1.local, c1.nome, c2.descricao, c2.area
from predio as c1, (
select local, descricao, area from salas as c1
where area = (select max(area) from salas as
c2 where area>0)
) as c2 where c2.id=c1.codigo;
E select c1.local, c1.nome, c2.descricao, max(c2.area)
from predio as c1 join salas as c2
on c2.codigo=c1.id
group by c1.local, c1.nome, c2.descricao
Comentário: Vamos procurar achar os erros das alternativas distintas da resposta da questão, analisaremos, portanto, na ordem que aparece na questão.
A O erro desta alternativa está no uso da função agregada sem que apareça o group by. Vejam também que não temos nenhuma função agregada descrita na cláusula select, por fim, a sintaxe do comando “having max(c2.area)” está incorreta, seria necessário comparar o valor de max(coluna) com uma constante ou outra variável, por exemplo max(c2.area) > 200;
B Veja que na alternativa B existe um erro lógico na comparação “c2.local=c1.id”, ela não faz sentido. Não traz para o resultado as tuplas necessárias.
C A alternativa C é a nossa reposta. Veja que primeiro é feita uma consulta interna para saber qual a sala que tem a área maior. Depois, outra subconsulta retorna os atributos que fazem parte da tupla que possui a sala com a maior área. Num terceiro momento, na consulta externa, recuperamos a informação do prédio, baseado na comparação do atributo mnemônico que funciona como atributo de ligação ou chave estrangeira, que relaciona as duas tabelas.
D A letra D usa o mesmo raciocínio da C, mas peca ao considerar a chave estrangeira outro atributo (c2.id=c1.codigo) desta forma não é possível correlacionar as duas tabelas.
E A alternativa E também não retorna o resultado adequado, precisaríamos de uma restrição sobre a função de agregação para retornar apenas a linha que possuísse o valor máximo, isso poderia ser feito por meio do uso da cláusula having e de uma subconsulta que retornasse o valor máximo.
Gabarito: C
Assinale a opção referente ao arquivo que grava todas as mudanças realizadas no DataBase e que é utilizado somente para recuperação de uma instância em um SGBD Oracle.
A Parameter log file
B Archive log file
C Undo file
D Control file
E Alert log file
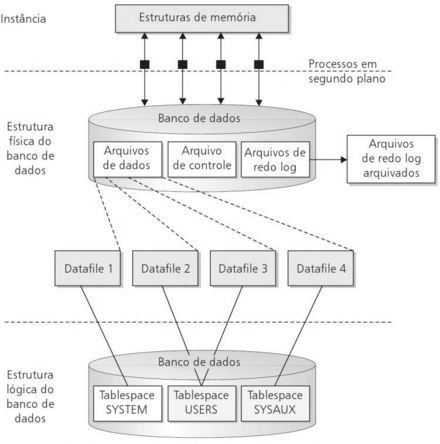
Comentário: Quando tratamos de estruturas físicas de armazenamento do Oracle é preciso entender que o Oracle usa algumas estruturas físicas para gerenciar armazenar os dados de transações do usuário. Algumas dessas estruturas de armazenamento, como os arquivos de dados, arquivos de redo e arquivos de redo logs arquivados, guardam os dados dos usuários. Outras estruturas, como arquivos de controle, mantêm o estado dos objetos no banco de dados. O arquivo de alerta baseado em texto e os arquivos de rastreamento contêm informações de log de eventos rotineiros e condições de erro do banco de dados. A figura abaixo mostra a estrutura física de armazenamento e sua relação com a estrutura lógica.
Vamos agora tratar um pouco dos arquivos de dados, de redo log, de controle e os arquivos de redo log arquivados:
Arquivos de dados: O Oracle Database deve conter pelo menos um arquivo de dados. Um arquivo de dados do Oracle corresponde a um único arquivo de sistema operacional no disco. Cada arquivo de dados é membro de um e somente um tablespace; entretanto uma tablespace pode ser constituída de por vários arquivos de dados. A exceção é um tablespace bigfile, que consiste de exatamente um arquivo de dados.
Um arquivo de dados Oracle pode se expandir automaticamente quando atingir o seu espaço alocado, se o DBA criou o arquivo de dados com o parâmetro AUTOEXTEND. O DBA também pode limitar a abrangência da expansão de um arquivo de dados específico por meio do parâmetro MAXSIZE. Seja qual for o caso, o tamanho do arquivo é limitado pelo volume do disco em que ele reside em última análise.
Arquivos de redo log: Sempre que forem adicionados, removidos ou alterados dados em uma tabela, índice ou em outro objeto do Oracle, uma entrada será gravada no arquivo de redo log atual. O Oracle Database deve possuir pelo menos dois arquivos de redo log, porque ele utiliza esses arquivos de modo circular. Quando um arquivo de redo log é preenchido com entradas de redo log, o arquivo de log atual é marcado como ACTIVE, se ele ainda for necessário para a recuperação da instância; caso contrário, ele será marcado como INACTIVE. O próximo arquivo de log na sequência é reutilizado a partir do início do arquivo e é marcado como CURRENT. Enfim, os arquivos redo logs armazenam as mudanças efetuadas no banco de dados para possibilitar a recuperação dos dados em caso de falhas.
Arquivos de controle: Os arquivos de controle contêm as informações necessárias para manter e verificar a integridade do banco de dados. Por exemplo, o arquivo de controle é utilizado para identificar os arquivos de dados e os arquivos de redo log. Um banco de dados Oracle deve possuir no mínimo um arquivo de controle.
Arquivos de redo log arquivados: São cópias off-line dos arquivos de redo log, que podem ser necessários em um processo de recuperação de falhas de mídia. O Oracle Database deve funcionar em dois modos: ARCHIVELOG e NOARCHIVELOG. Quando o banco de dados estiver no modo NOARCHIVELOG, a reutilização circular dos arquivos de redo log (também conhecidos como arquivos de redo log online) significa que as entradas de redo não estarão disponíveis se ocorrer uma falha na unidade de disco. Trabalhar no modo NOARCHIVELOG não protege a integridade do banco de dados por ocasião de uma falha na instância ou no sistema. Em contraste, o modo ARCHIVELOG envia um arquivo de redo log preenchido para um ou mais destinos especificados e pode ficar disponível para reconstrução do banco a qualquer momento, se ocorrer uma falha de mídia do banco de dados. Veja que estamos tratando da questão juntamente desse tipo de arquivo. Podemos marcar, então, com segurança a alternativa B como resposta.
Gabarito: B
Assinale a opção que apresenta o parâmetro que deve ser ativado com TRUE, no arquivo init.ora no SGBD Oracle, para que os relatórios do TKPROF incluam informações de tempo.
A TIMED_STATISTICS
B STAT_TIME
C TIMINGS
D TIME_QUERY
E STATISTICS
Comentário: O processo de inicialização de um banco de dados Oracle é feito a partir da leitura dos arquivos de inicialização. Há dois tipos de arquivos: o PFILE que é um arquivo texto conhecido pelo init.ora e o SPFILE que é um arquivo de parâmetro do servidor conhecido como spfile.ora.
O PFILE é um arquivo texto, dentro dele estão guardados os parâmetros de configuração do banco de dados. Entre outras coisas estes parâmetros informam a quantidade de memória a ser alocada, onde estão os arquivos do banco de dados e onde gravar os arquivos necessários ao funcionamento do banco. Como o PFILE é um arquivo de texto puro, ele pode ser facilmente editado no VI do UNIX ou no Notepad do Windows. Normalmente ele tem o nome de init.ora, onde SID é a identificação de seu banco de dados, exemplo se seu SID é bdconcurso então seu PFILE será nomeado como initbdconcurso.ora.
O TKPROF é um programa que formata um arquivo de TRACE SQL bruto em um arquivo mais amigável. O programa lê o arquivo de rastreamento e cria um arquivo que tem as seguintes seções: Cabeçalho, Corpo e Resumo.
Para que o resultado do TRACE possua o resultado solicitado pela questão temos que entender os parâmetros que podem ser definidos, alguns deles dentro do arquivo init.ora. A lista abaixo detalha os parâmetros que permitem informações sobre tempo, local do diretório, tamanho máximo de arquivo de rastreamento e proteções de acesso a arquivos de rastreamento a serem especificados e respeitados quando SQL Trace estiver habilitado.
TIMED_STATISTICS: Especifica se estatísticas de tempo são coletadas ou não. Definidas pelos valores TRUE ou FALSE associado a variável. Observe que está é a nossa resposta.
MAX_DUMP_FILE_SIZE: Especifica o tamanho máximo do arquivo de rastreio de SQL em blocos do sistema operacional se apenas um número aparecer, ou em bytes de as letras M ou B aparecerem, ou ainda ilimitado caso a variável seja definida como UNLIMITED.
USER_DUMP_DEST: Especifica o diretório onde o Trace SQL é armazenado.
_TRACE_FILES_PUBLIC: Especifica se o arquivo de rastreamento é escrito com as configurações de acesso público. Os valores válidos são TRUE ou FALSE.
Gabarito: A
A respeito de sistemas de suporte a decisão, assinale a opção correta.
A As ferramentas de ETL têm como objetivo efetuar extração, transformação e carga de dados vindos de uma base transacional para um data warehouse (DW). No processo de extração, que é o mais demorado dos três, ocorre a limpeza dos dados, a fim de garantir a qualidade do que será posteriormente carregado na base do DW.
B Os operadores de navegação drill-down (navegam entre as hierarquias diminuindo o nível do detalhe, por exemplo: município > estado) e roll-up (navegam entre as hierarquias aumentando o nível do detalhe, por exemplo: estado > município) são considerados básicos e estão implementados em todas as ferramentas de OLAP.
C As bases de dados criadas para atender ao data warehouse (DW) são do modelo relacional (E/R), em que as tabelas representam dados e relacionamentos e são altamente normalizadas.
D Nos processos de análise de inferência, representados pelo data mining, ocorrem buscas de informação com base em algoritmos que objetivam o reconhecimento de padrões escondidos nos dados e não revelados por outras abordagens.
E Em uma arquitetura de data warehouse (DW), os dados são coletados das fontes operacionais na fase de extração, trabalhados na fase de transformação (ou staging) e carregados no DW na fase de carga. Quando necessário, um banco de dados temporário, preparatório para a carga no DW, poderá ser criado na fase de extração, com características relacionais.
Comentário: Vamos comentar a alternativas acima
A Na extração não acontece a limpeza dos dados, para tal tarefa temos, dentro do processo de ETL, a etapa de transformação.
B A alternativa troca os conceitos de DRILL-DOWN e ROLL-UP, principalmente em relação a navegação sobre a hierarquia dos dados.
C Nem todas as bases de dados de DW são relacionais, elas também podem ser dimensionais. Outra característica é o fato de que, quando utilizamos a modelagem multidimensional, as tabelas encontram-se desnormalizadas. Alternativas incorreta.
D Apresenta uma definição possível e correta para mineração de dados, sendo, portanto a reposta à questão.
E A área de staging é um espaço de armazenamento temporário que pode ser usado, tanto para implementação de bases de dados relacionais temporárias, quanto para armazenamento de arquivos planos ou XML. Se observarmos essa alternativa pode ser respondida pelo texto da wikipedia que afirma que o staging não necessariamente é estruturado de forma relacional, como sugere a questão.
Gabarito: D
Acerca de data mining, assinale a opção correta.
A A fase de preparação para implementação de um projeto de data mining consiste, entre outras tarefas, em coletar os dados que serão garimpados, que devem estar exclusivamente em um data warehouse interno da empresa.
B As redes neurais são um recurso matemático/computacional usado na aplicação de técnicas estatísticas nos processos de data mining e consistem em utilizar uma massa de dados para criar e organizar regras de classificação e decisão em formato de diagrama de árvore, que vão classificar seu comportamento ou estimar resultados futuros.
C As aplicações de data mining utilizam diversas técnicas de natureza estatística, como a análise de conglomerados (cluster analysis), que tem como objetivo agrupar, em diferentes conjuntos de dados, os elementos identificados como semelhantes entre si, com base nas características analisadas.
D As séries temporais correspondem a técnicas estatísticas utilizadas no cálculo de previsão de um conjunto de informações, analisando-se seus valores ao longo de determinado período. Nesse caso, para se obter uma previsão mais precisa, devem ser descartadas eventuais sazonalidades no conjunto de informações.
E Os processos de data mining e OLAP têm os mesmos objetivos: trabalhar os dados existentes no data warehouse e realizar inferências, buscando reconhecer correlações não explícitas nos dados do data warehouse.
Comentário: Mais uma vez, teceremos comentários sobre cada uma das alternativas acima.
A Sabemos que a mineração de dados pode acontecer sobre qualquer tipo de arquivo de dados. Lembrem-se a possibilidade de textmining que não tem necessidade de dados armazenados em um Dw. Alternativa errada!
B Na alternativa B existe uma avalanche de conceitos misturados: redes neurais, que fazem parte do conjunto de assuntos relacionados a inteligência artificial; técnicas estatística e arvore de decisão. Cada técnica de mineração é usada com um propósito especifico, por exemplo, a classificação vai permitir que você classifique novas entradas de acordo com um conjunto pré-determinado de saídas, que foram construídos em uma etapa anterior do processo. A questão peca por misturar vários conceitos.
C Criar clusters, ou seja, agrupar subconjuntos de dados de acordo com alguma semelhança entre eles. Essa é a nossa resposta.
D Uma serie temporal deve considerar a sazonalidade, pela lei da oferta e demanda, se você percebe que as vendas aumentam no Natal, você pode aumentar o preço ou o estoque. O fato de desconsiderar a sazonalidade torna a questão incorreta.
E Os processos de OLAP e Data mining são diferentes em relação a complexidade e resultados esperados. OLAP é uma ferramenta de consulta em bases de dados analíticas, ele visa extrair informações por meio de queries e utilizando as operações sobre os cubos de dados, mas não aplicam algoritmos específicos neste processo. Data Mining é bem mais complexo que OLAP, ele busca padrões em grandes volumes de dados por meio de técnicas estatísticas e de algoritmos de inteligência artificial, por exemplo. Sendo assim não é possível comparar de forma tão simplista quando a alternativa tentou fazer, por isso, a letra E está incorreta.
Gabarito: C
Acerca de SQL (structured query language), assinale a opção correta.
A A otimização semântica de consultas utiliza restrições existentes no banco de dados (como atributos únicos, por exemplo) com o objetivo de transformar um SELECT em outro mais eficiente para ser executado.
B Quando os registros de uma tabela estão ordenados fisicamente em um arquivo, segundo um campo que também é campo-chave, o índice primário passa a se chamar índice cluster.
C Em uma mesma base de dados, uma instrução de SELECT com união de duas tabelas (INNER JOIN) e uma instrução de SELECT em uma tabela utilizando um SELECT interno de outra tabela (subquery) produzem o mesmo resultado e são executadas com o mesmo desempenho ou velocidade.
D A normalização de dados é uma forma de otimizar consultas SQL, ao apresentar um modelo de dados com um mínimo de redundância. Isso é atingido quando o modelo estiver na quinta forma normal (5FN).
E Para obter a quantidade de linhas que atendem a determinada instrução SQL, o processo mais eficiente e rápido é executar o comando SELECT e aplicar uma estrutura de loop para contar as linhas resultantes.
Comentário: Vamos então analisar cada uma das alternativas acima.
A Uma transformação que é válida somente porque certa restrição de integridade está em efeito é chamada transformação semântica e a otimização resultante é chamada otimização semântica. A otimização semântica pode ser definida como o processo de transforma uma consulta especificada em outra consulta, qualitativamente diferente, mas da qual se garante que produzirá o mesmo resultado que a original, graças ao fato de que os dados com certeza satisfazem a uma determinada restrição de integridade. Vejam que a definição está de acordo com o descrito na alternativa, logo essa é a nossa resposta.
B Quando tratamos de índexes podemos de forma resumida classifica-los em três categorias: Índice primário, baseado na chave de ordenação; Índice de agrupamento (clustering), baseado no campo de ordenação não-chave de um arquivo e Índice secundário, baseado em qualquer campo não ordenado de um arquivo. Observem que a alternativa tenta confundir a definição de índice primário com índice de cluster.
C Não existe nenhuma garantia para saber qual das duas instruções será executada de forma mais rápida, vai depender, por exemplo, do perfil dos dados, do algoritmo utilizado pelo SGBD na execução das consultas e da forma como os índices são criados para cada uma delas. Desta forma, a alternativa está incorreta.
D A normalização é uma atividade que reduza a redundância dos dados dentro do banco de dados e as anomalias de atualização. Não existe um compromisso do processo de normalização com a otimização de consultas. Se lembramos da estrutura dos modelos dimensionais, sabemos que eles são desnormalizados por uma questão de performance.
E Mais uma vez, a velocidade da consulta ou seu desempenho vai depender da forma como os dados e os índices estão estruturados. Existem vários algoritmos que pode trazer a quantidade de valores possíveis, escolher qual o melhor deles é uma tarefa delicada. Desta forma, a alternativa encontra-se errada.
Gabarito: A
Espero que tenham gostado, qualquer dúvida estou às ordens,
Thiago Cavalcanti
Concurso GCM Manaus AM oferece 590 vagas + CR de nível médio! Foi divulgado o…
A Secretaria Estadual de Educação do Paraná publicou um novo edital de Processo Seletivo Simplificado…
Concurso para a GCM Itupeva SP oferece oportunidades de nível médio. Provas em 27 de…
Cerca de 410 aprovados no último concurso BNB já foram nomeados! O Banco do Nordeste…
O concurso BNB pode ganhar um novo edital após o Banco do Nordeste concluir todas…
Se você tinha medo de perder alguma informação importante, não se preocupe! Aqui você confere…
{kind=link}