Beatriz Lima Nogueira
Aprovada no concurso CGE para o cargo de Auditor Estadual de Controle - Correição e Combate à Corrupção
Aprovada Concurso CGE SP: Beatriz Lima Nogueira
Olá, pessoal. Tudo certo? No artigo de hoje veremos um resumo sobre Data Warehouse para SEFAZ-SP.
O artigo será dividido da seguinte forma:
Sem mais delongas, vamos lá.
Dando início ao resumo sobre Data Warehouse para SEFAZ-SP, vamos primeiro falar sobre um conceito importante, Business Intelligence (Inteligência de Negócio).
Business Intelligence (BI) é um conjunto de tecnologias, processos e práticas que transformam dados brutos em informações significativas e úteis para apoiar a tomada de decisões empresariais.
O objetivo do BI é fornecer insights acionáveis que ajudem as organizações a entender melhor seu desempenho, identificar tendências, descobrir oportunidades de crescimento e antecipar desafios futuros.
Além disso, é válido conhecer as habilidades que estão relacionadas ao processo de gerenciamento de conhecimento e análise de dado.
Ainda, podemos diagramar o BI em quatro grandes componentes, também conhecida como Arquitetura de Business Intelligence.
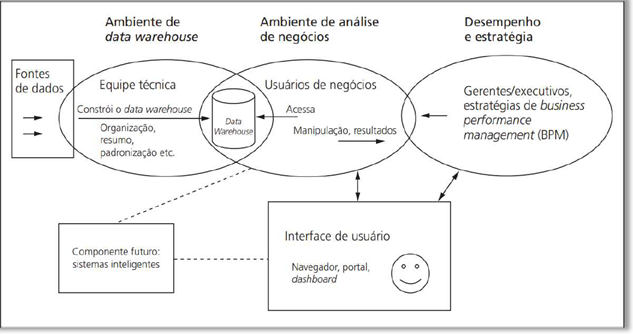
Agora que entendemos o conceito de BI, podemos adentrar em DW.
Prosseguindo no resumo sobre Data Warehouse para SEFAZ-SP, vejamos sobre o Data Warehouse (DW).
Data Warehouse (DW): sistema de armazenamento de dados projetado para permitir análises e relatórios eficientes de grandes volumes de dados de diferentes fontes dentro de uma organização. É uma coleção centralizada de dados orientada a assuntos, que são organizados e otimizados para suportar processos de tomada de decisão e análises estratégicas.
Atenção, pois a grande parte das questões são focadas nas características do DW, assim vamos aprofundar um pouco nos conceitos.
Características essenciais:
Orientado por Assunto: os dados são organizados em torno de assuntos relevantes para a organização, em vez de refletirem a estrutura de sistemas transacionais. Isso facilita a análise e compreensão dos dados para tomada de decisões.
Não-Volátil: os dados em um DW são carregados e armazenados de forma estática, ou seja, não são alterados ou atualizados com frequência. Em vez disso, são historicamente preservados para permitir análises retroativas e comparativas ao longo do tempo.
Integrado: O DW integra dados de diversas fontes, como sistemas operacionais e departamentais, em uma única fonte de verdade. Isso garante consistência e uniformidade nos dados, permitindo análises holísticas da organização.
Histórico: Além de armazenar dados atuais, o Data Warehouse também mantém um histórico de dados ao longo do tempo. Isso permite a análise de tendências, padrões e mudanças ao longo do tempo, fornecendo insights valiosos para tomada de decisões estratégicas.
De forma resumida então,
Continuando no resumo sobre Data Warehouse para SEFAZ-SP, agora vejamos os tipos de DW.
Enterprise Data Warehouse (EDW):
Operational Data Store (ODS):
Data Marts (DM):
Saibamos também diferenciar as abordagens de Inmon e Kimball, tema recorrente em prova!
Em resumo, a abordagem de Inmon preconiza a construção de um Data Warehouse corporativo centralizado e integrado, enquanto a abordagem de Kimball enfatiza a entrega rápida de valor aos usuários por meio da construção de data marts dimensionais independentes.

Ambas as abordagens têm seus méritos e são amplamente utilizadas na prática, com base nas necessidades e na cultura organizacional de cada empresa.
Ainda no Data Warehouse para SEFAZ-SP, vejamos de forma esquemática o processo em um Data Warehouse.
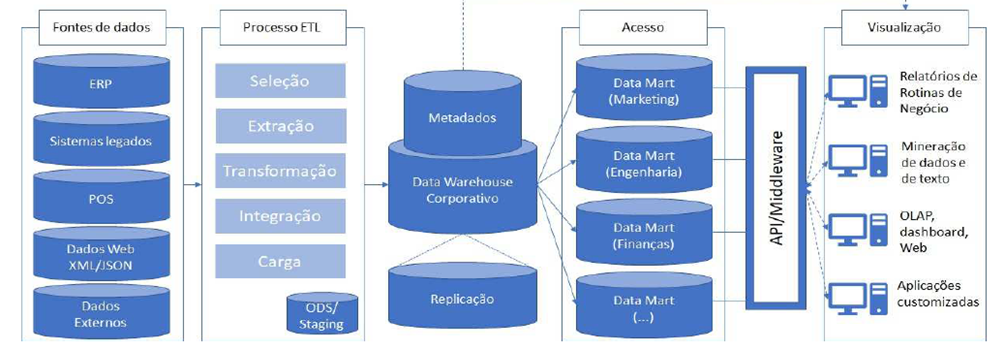
Não se trata de um tema muito cobrado, com exceção ao Processo ETL.
Processo ETL
Extração (Extract):
Transformação (Transform):
Carregamento (Load):
Outro ponto que está sendo cobrado em prova é a diferença entre ETL e ELT.
Com o avanço das tecnologias de armazenamento e processamento de dados, bem como o surgimento de soluções de Data Warehousing na nuvem e data lakes, a abordagem ELT tem ganhado popularidade.
ELT oferece vantagens significativas em termos de escalabilidade, flexibilidade e custo, especialmente em cenários onde a capacidade de processamento e armazenamento do Data Warehouse é abundante e os dados podem ser transformados de forma eficiente dentro do próprio ambiente do Data Warehouse ou em plataformas de big data.
Vejamos uma tabela comparativa entre os critérios.

Para finalizar o resumo sobre Data Warehouse para SEFAZ-SP, vejamos sobre Pipeline de Dados.
Pipeline de dados: é um conceito que descreve o processo de movimento e transformação de dados de uma fonte para um destino, geralmente em um ambiente de computação distribuída.
É uma série de etapas sequenciais que envolvem a extração, transformação e carga (ETL) de dados para uso em análises, relatórios, processamento ou armazenamento.
Assim, podemos citar algumas vantagens na utilização de Pipeline de Dados.
Pipelines de Processamento de Fluxo (Stream Processing Pipelines): Nesse tipo de pipeline, os dados são processados conforme são gerados, de forma contínua e em tempo real. São ideais para casos de uso em que é necessário processar dados em tempo real, como análise de streaming, detecção de anomalias em tempo real, processamento de eventos, monitoramento em tempo real, entre outros.
Pipelines de Processamento em Lote (Batch Processing Pipelines): Nesse tipo de pipeline, os dados são processados em lotes, ou seja, em grupos de dados que são coletados e processados de uma vez. Os pipelines de processamento em lote são úteis para casos de uso em que a latência não é crítica e é aceitável esperar pelo processamento completo dos dados antes de obter os resultados.
Ainda, caso tenha ficado confuso, entenda que um pipeline de dados abrange todo o fluxo de dados, incluindo ingestão, processamento e consumo, enquanto o processo ETL é uma parte específica desse pipeline que se concentra na extração, transformação e carga de dados. O ETL é apenas uma das muitas etapas possíveis em um pipeline de dados mais amplo.
Pessoal, chegamos ao final do resumo sobre Data Warehouse para SEFAZ-SP, tema relevante para sua prova.
Assim, não deixe de estudar o assunto na íntegra por nossas aulas, além de treinar por meio de questões de concurso em nosso sistema de questões.
Gostou do artigo? Siga-nos
https://www.instagram.com/resumospassarin/
Prepare-se com o melhor material e com quem mais aprova em Concursos Públicos em todo o país!