Vládia de Souza Brito Zanola
Aprovada no concurso SEFAZ GO para o cargo de Auditor Fiscal
Aprovada Concurso SEFAZ GO: Vládia de Souza Brito Zanola
Vamos retomar a nossa série especial de temas sobre Ciência de Dados. No artigo de hoje, falaremos sobre técnicas de pré-processamento de linguagem natural.
O tópico é uma das grandes apostas para as provas específicas da área de TI e/ou concorridas da área geral, em razão de sua cobrança nos últimos anos. Dessa forma, os alunos que estudam para essas provas não podem negligenciá-lo de jeito nenhum.
Apesar de ser um tema relativamente recente, o processamento de linguagem natural não é tão simples e há muito conteúdo para confundir. Como sempre, vamos tentar explicar tudo de uma forma clara e direta, para você não perder muito tempo. Veja o nosso roteiro:
Atendendo a pedidos, o artigo é curtinho, respeitando o nosso compromisso de trazer uma leitura direta a você. Ou seja, hoje não tem desculpas, concurseiro. Esperamos você nas próximas seções. Até já!
Tempo de leitura aproximada: 5 a 10 minutos
O processamento de linguagem natural (PLN) é um ramo da Inteligência Artificial que utiliza técnicas de aprendizado de máquina para compreender e manipular automaticamente a linguagem humana, principalmente por meio de interpretação de texto.
Você Sabia? Aprendizado de máquina, também conhecido como machine learning, consiste em mecanismos para que uma máquina aprenda e evolua constantemente. A máquina pode receber apoio para o aprendizado, por meio de uma apresentação prévia dos dados, ou ter que aprender sozinha.
Apesar de o processamento de linguagem natural estar oficialmente na Inteligência Artificial, frequentemente as bancas cobram dentro dos tópicos de Ciência de Dados, haja vista que a linguagem humana e suas derivações textuais são tipos de dados.
Com o processamento de linguagem natural, é possível analisar textos, identificar seus significados e tomar decisões a partir desses resultados observados. Ele é muito utilizado por empresas, especialmente para entender opiniões de clientes e prever tendências futuras.
Veja uma esquematização de como ocorre o processamento de linguagem natural.
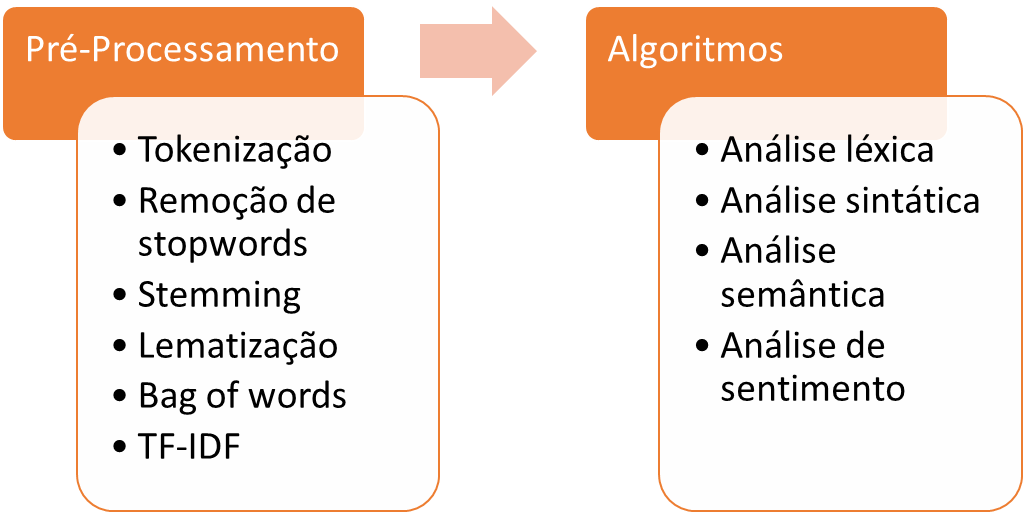
Concurseiro, nós somos sinceros. Saiba que as bancas cobram muito menos o desenvolvimento de algoritmos do que as técnicas de pré-processamento. É por isso que estamos focando nas técnicas neste artigo.
Porém, isso não significa que os algoritmos não caiam. Eles caem, mas com uma probabilidade menor. Em outras palavras, se você tem pouco tempo, foque nas técnicas de pré-processamento. Dessa forma, já conseguirá garantir muitas questões.
O processamento de linguagem natural trabalha com algumas técnicas de pré-processamento. Essas técnicas buscam manipular o texto antes do processamento propriamente dito começar.
Mais uma vez, as bancas gostam de cobrar isso (principalmente a FGV nos concursos mais “caveiras”). Como nossa proposta neste artigo se pauta na objetividade, vamos falar brevemente sobre cada uma delas.
Tokenização: o texto é dividido em pequenas unidades, chamadas tokens. Na prática, cada token corresponde a um termo que aparece no texto.
Vamos ver um exemplo simples.
Exemplo: Eu espero a sua mensagem ansiosamente.
No exemplo acima, cada termo (“Eu”, “espero”, “a” etc.) corresponde a um token. Assim, teríamos 6 tokens no texto apresentado.
Remoção de stopwords: esta técnica de pré-processamento de linguagem natural visa eliminar palavras irrelevantes para o texto, também denominadas de stopwords. Na prática, são artigos, preposições, pronomes do texto etc.
Vamos voltar ao nosso exemplo.
Exemplo: Eu espero a sua mensagem ansiosamente.
De acordo com a explicação, os tokens que podem ser considerados stopwords no texto são “Eu” (pronome reto), “a” (artigo definido), “sua” (pronome possessivo).
Após a remoção das stopwords, ficaríamos com “espero”, “mensagem” e “ansiosamente”. Veja que é possível entender a mensagem mesmo com apenas 3 palavras.
Stemming: esta técnica remove a flexão dos tokens, mantendo apenas o radical ou a raiz. Isso facilita a identificação do seu significado. Pode ser aplicada em palavras que admitem algum tipo de derivação e precisam ser simplificadas, tais como verbos, plurais etc.
Exemplo: “espero” => “esper”
“mensagem” => “mensagem”
“ansiosamente” => “ansiosa”
Nas palavras acima, veja que podemos aplicar o stemming em “espero” (verbo no presente) e “ansiosamente” (advérbio de modo). Não faria diferença na aplicação da palavra “mensagem”, pois esta é um substantivo não flexionado.
Lematização: faz o inverso do stemming, considerando os tokens sem as flexões aplicadas. Na prática, considera infinitivos de verbos, substantivos e advérbios no masculino singular etc.
Exemplo: “esper” => “esperar”
“mensagem” => “mensagem”
“ansiosa” => “ansioso”
Bag of words: técnica vetorial de pré-processamento de linguagem natural mais clássica, que considera a frequência de cada token no texto. Também é conhecida como saco de palavras.
Vamos ver um exemplo um pouco maior para ficar mais claro.
Exemplo: “Eu espero a sua mensagem ansiosamente. Eu mandei uma mensagem há alguns meses e você não respondeu. Como eu sei que você recebeu a mensagem, então não há desculpa.”
Deixando a briga de lado, a nossa ideia é contar quantas vezes cada token aparece. Mas antes, precisamos determinar quais são os tokens. Vamos continuar com o exemplo:
tokens = [“eu”, “espero”, “a”, “sua”, “mensagem”, “ansiosamente”, “mandei”, “uma”, “há”, “alguns”, “meses”, “e”, “você”, “não”, “respondeu”, “como”, “sei”, “que”, “recebeu”, “então”, “desculpa”]
Conhecidos os tokens, vamos fazer a contagem. As frequências podem ficar no mesmo vetor de tokens ou em uma estrutura separada. Para facilitar a explicação, vamos separar:
frequencias = [3, 1, 2, 1, 3, 1, 1, 1, 2, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1]
Em outras palavras, “eu” aparece 3 vezes, “espero” aparece 1 vez, “a” aparece 2 vezes e assim por diante. Veja que não é tão difícil, mas precisa conhecer a técnica.
TF-IDF: técnica vetorial de pré-processamento de linguagem natural que analisa a frequência dos tokens em uma amostra (TF) em comparação com a ocorrência dos tokens em outros textos (IDF). O objetivo é identificar palavras raras que aparecem.
Observe as fórmulas abaixo:
Frequência de Termos (TF) = Número de vezes que o token aparece no documento / número de tokens no documento
Vamos considerar o exemplo anterior, da briga de casal. Suponha que o número de tokens do documento é 21. Vamos então calcular o TF de cada um dos tokens:
TF = [3/21, 1/21, 2/21, 1/21, 3/21, 1/21, 1/21, 1/21, 2/21, 1/21, 1/21, 1/21, 2/21, 2/21, 1/21, 1/21, 1/21, 1/21, 1/21, 1/21, 1/21]
TF = [0,14; 0,05; 0,09; 0,05; 0,14; 0,05; 0,05; 0,05; 0,09; 0,05; 0,05; 0,05; 0,09; 0,09; 0,05; 0,05; 0,05; 0,05; 0,05; 0,05; 0,05]
Frequência Inversa nos Documentos (IDF) = Número total de documentos / número de documentos em que o token aparece
No nosso cenário, só estamos trabalhando com 1 documento. Na hora da prova, a questão irá fornecer dados sobre outros documentos para você fazer as contas. Mesmo assim, vamos deixar os cálculos indicados para você ver como seria:
IDF = [1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1, 1/1]
IDF = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Para calcular o TF-IDF, basta multiplicar as frequências, utilizando a fórmula abaixo:
TF-IDF = Frequência de Termos (TF) * Frequência Inversa nos Documentos (IDF)
TF-IDF= [0,14; 0,05; 0,09; 0,05; 0,14; 0,05; 0,05; 0,05; 0,09; 0,05; 0,05; 0,05; 0,09; 0,09; 0,05; 0,05; 0,05; 0,05; 0,05; 0,05; 0,05] * [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
TF-IDF= [0,14; 0,05; 0,09; 0,05; 0,14; 0,05; 0,05; 0,05; 0,09; 0,05; 0,05; 0,05; 0,09; 0,09; 0,05; 0,05; 0,05; 0,05; 0,05; 0,05; 0,05]
Vamos fechar o artigo com um mapa mental caprichado para apoiar a sua memorização. Mesmo que você não tenha entendido todas as técnicas da seção anterior, não deixe de ver a imagem para apoiar os seus estudos. Divirta-se!
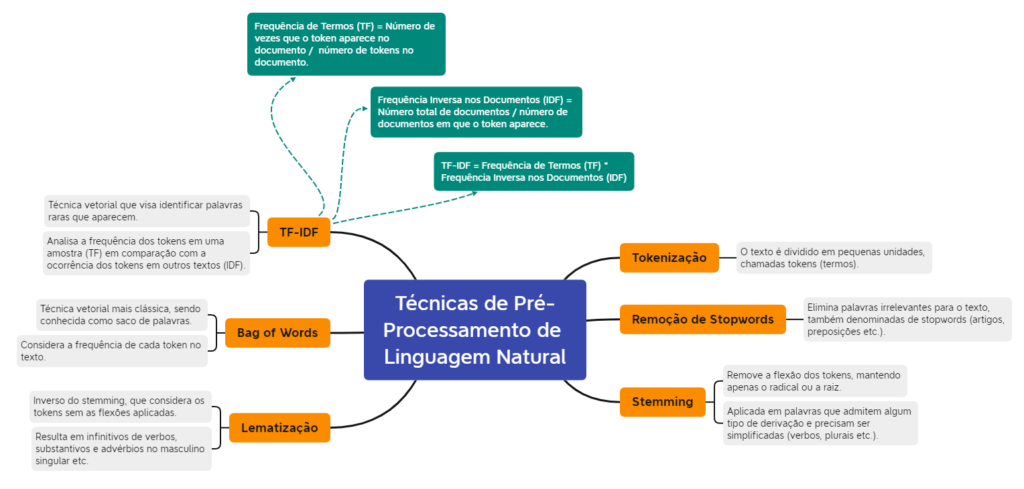
Em suma, o artigo de hoje abordou técnicas de pré-processamento de linguagem natural, um dos temas mais cobrados de Ciência de Dados. Se você entendeu tudo de imediato, então parabéns!
Caso contrário, não fique desanimado. Alguns assuntos parecem realmente complicados à primeira vista. Se você quiser aprofundar o conteúdo ou tirar dúvidas específicas, busque o material do Estratégia Concursos.
Nós oferecemos diversos cursos em pdf, videoaulas e áudios para você ouvir onde quiser. Saiba mais por meio do link http://www.estrategiaconcursos.com.br/cursos/.
Por fim, recomendamos também que você faça muitas questões para treinar os tópicos apresentados. O acesso ao Sistema de Questões do Estratégia Concursos é feito pelo link: https://concursos.estrategia.com/.
Bons estudos e até a próxima!
Cristiane Selem Ferreira Neves é Bacharel em Ciência da Computação e Mestre em Sistemas de Informação pela Universidade Federal do Rio de Janeiro (UFRJ), além de possuir a certificação Project Management Professional pelo Project Management Institute (PMI). Já foi aprovada nos seguintes concursos: ITERJ (2012), DATAPREV (2012), VALEC (2012), Rioprevidência (2012/2013), TJ-RJ (2022) e TCE-RJ (2022). Atualmente exerce o cargo efetivo de Auditora de Controle Externo – Tecnologia da Informação no Tribunal de Contas do Estado do Rio de Janeiro (TCE-RJ), além de ser produtora de conteúdo dos Blogs do Estratégia Concursos, OAB e Carreiras Jurídicas.